 Apache Spark History Server - Usage and Configuration Instructions
Apache Spark History Server - Usage and Configuration Instructions
About
Apache Spark History Server for AWS Glue / Apache Spark event logs kept on Amazon S3, this AMI will allow you to quickly deploy and integrate slightly modified open source Apache Spark History Server for better AWS integration and easier user experience. You can use the web based user interface to monitor and debug Apache Spark Jobs, AWS Glue ETL jobs running on the AWS Glue job system, and also Spark applications running on AWS Glue development endpoints. The Spark History Server UI enables you to check the following for each job:
- The event timeline of each Spark stage
- A directed acyclic graph (DAG) of the job
- Physical and logical plans for SparkSQL queries
- The underlying Spark environmental variables for each job
Table of Contents
- Highlights
- Accessing to Spark History Server
- Spark History Server Configuration
- Spark UI Access
- How to use it with AWS Glue
Highlights
- Customized / integrated configuration panel for better AWS integration
- Support for all AWS Glue versions (Glue 4.0 - Spark 3.3.0, Glue 3.0 - Spark 3.1.1, Glue 2.0 - Spark 2.4.3, Glue 1.0 - Spark 2.4.3)
- Ability to switch between Glue - Spark engine versions using web browser
- Extensive S3 access support; instance roles, permanent user credentials, temporary credentials / session tokens
- Ability to reconfigure Spark Event Logs S3 path online
- Auto restart of Spark Event History Server after configuration changes
- Observe Status and Logs of Spark Event History Server remotely even if it is in failed state
Accessing to Spark History Server
After the deployment, you can access the Spark History Server interface via a browser using HTTPS (port 443) or HTTP (port 80) protocols; for instance, https://public_dns_name or http://public_dns_name. If your EC2 instance has no public name (running inside a private VPC), you can access to the spark history server web interface via; https://private_dns_name or http://private_dns_name. Alternatively you can use attached public/private IP addresses instead of DNS names. In both scenarios, you will need to make sure that the traffic is routable between client and the EC2 instance. Security group attached to the EC2 instance should allow at least TCP port 443 (HTTPS) or TCP port 80 (HTTP) inbound access from the client location you are trying to access from.
When you successfully connect to the web interface, the Spark History Server main page is displayed as shown below

By default, the server is configured with a self-signed SSL certificate for HTTPS communication. Therefore, as shown below, you may receive a security / certificate warning in web browsers when using HTTPS access.
If you would like to proceed with the self-signed certificate, you can click Advanced button and then Accept the Risk to continue.
Spark History Server Configuration
By default the Spark History Server configured to process the spark event-logs kept locally on EC2 instance (file:///tmp/spark-events). Spark log events manually copied to the EC2 instance's "/tmp/spark-events" directory can become browsable in the history server. However it is recommended to directly get the spark event logs from S3 for ease of use and flexibility. To configure your Spark History Server please click Configuration link present in the home page.
Configuration page displays the as-is settings and allows you to modify them
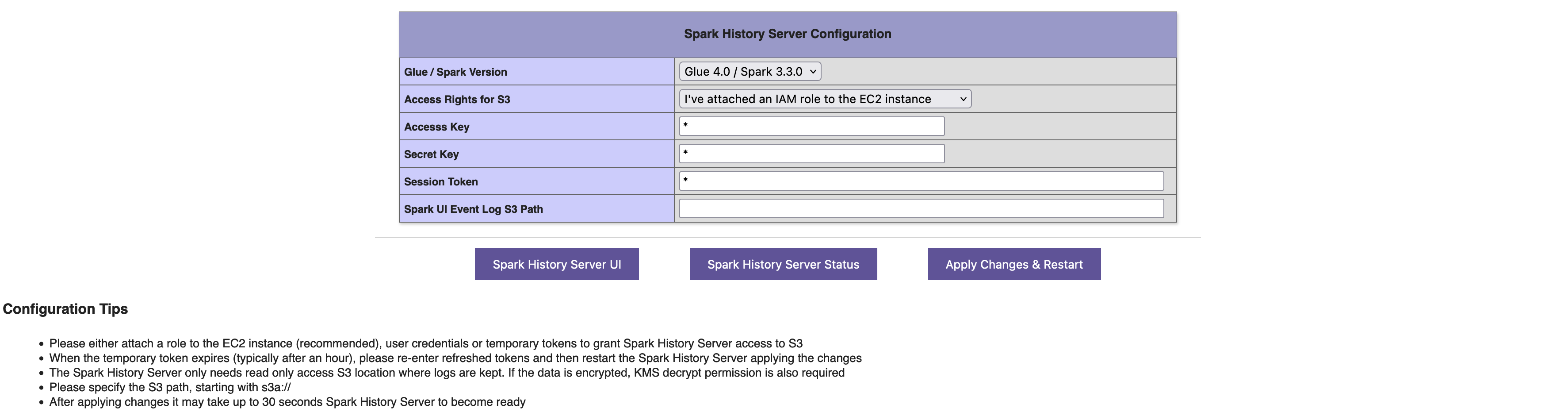
It is recommended to keep the AWS Glue / Spark engine version as the latest one. However, if you prefer you can switch back to older Spark engine versions incase you have difficulty browsing logs of older versions of AWS Glue has produced

Spark History Server needs to have read permissions for the S3 path hosting the spark event logs. Read permission can be provided either attaching an instance role to the EC2 instance (first option in the combobox below - RECOMMENDED from security perspective). Alternatively you can create an IAM user / use an existing IAM user. In that case you can choose the second option in the combobox shown below. Then you can enter the programmatic access key and secret key information. Spark History Server configuration wizard also supports temporary session token usage. In that case, you can select the last option from the combobox, and then you can configure the access key, secret key and session token details to be used by the Spark History Server. In all these options Read Only access to the S3 path, and KMS decrypt permissions (if the logs are KMS encrypted) is required only. You should keep it as least privieleged.

Specifiying Spark UI Event Log Path is the most important setting you need to modify. While configuring local paths on EC2 instance, the path should start with "file:///". However it is recommended to directly get the spark event logs from S3 for ease of use and flexibility. For S3 paths, it should be entered starting with s3a:/// ending with /, for example ; s3a:///bucketname/prefixes/
After configuration changes, you should click on Apply Changes & Restart button, which will save settings, restart the spark history server and display service status. In case, any configuration issues or S3 access issues, it may fail to start and display Failed state as shown below. In that case, please reconfigure, check the roles/access permissions; for instance, whether the session token you provided has expired or not. After configuring / correcting the issues, you can restart the server by clicking Apply Changes & Restart button again.

Spark UI Access
When you configure the Spark History Server correctly, the UI interfaces shows the Event Log Directory being used. In case you don't see any completed application log, please click on Show Incomplete Applications button. Incomplete applications are typically the section you will see where Glue jobs' spark event logs accumulated

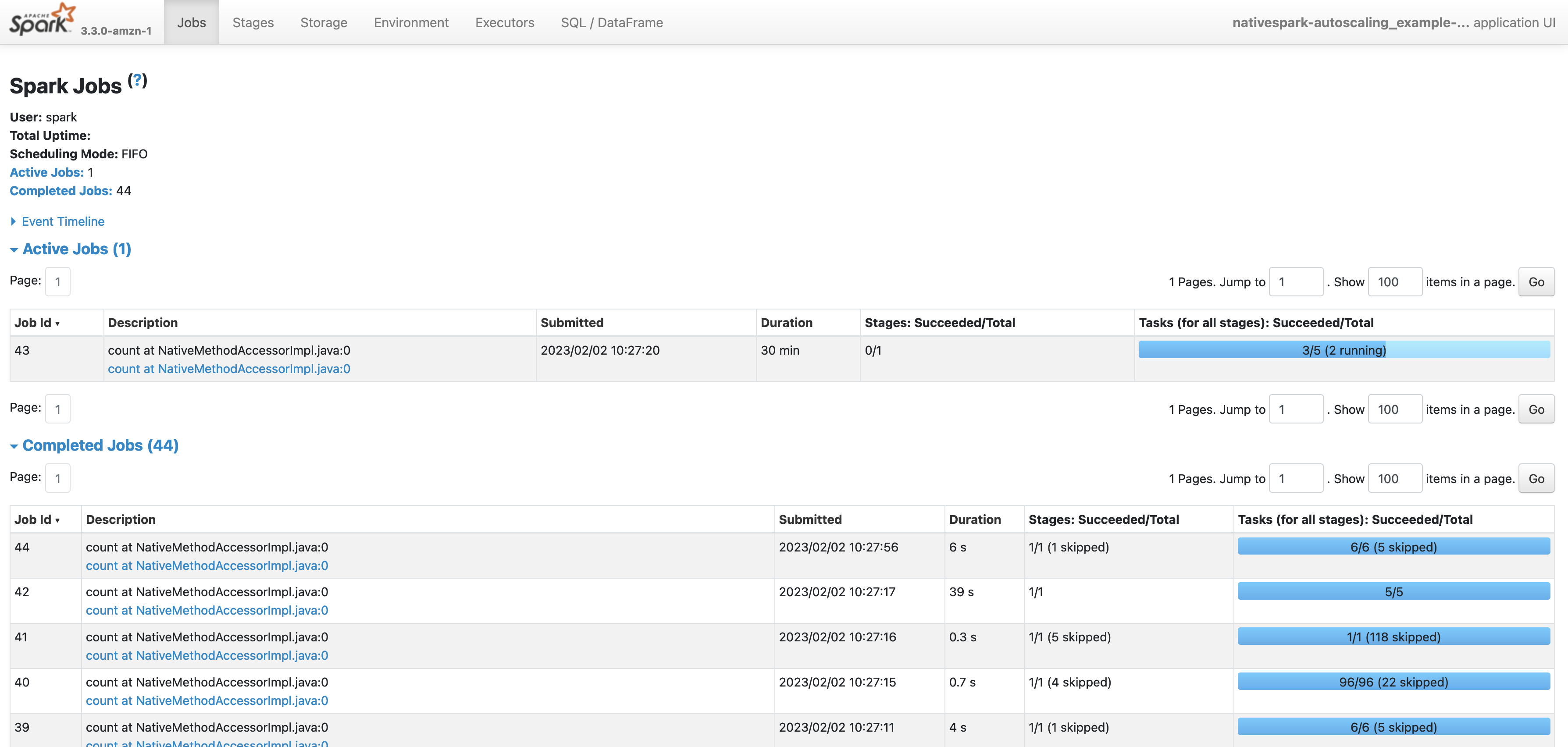
Depending on number of Glue jobs you run, you will see list of applications in the incomplete applications list. You can click the one you desire to analyse

Jobs tab shows the stages of your Glue Job
SQL / Data Frame tab shows the execution diagram of relevant Spark - SparkSQL actions
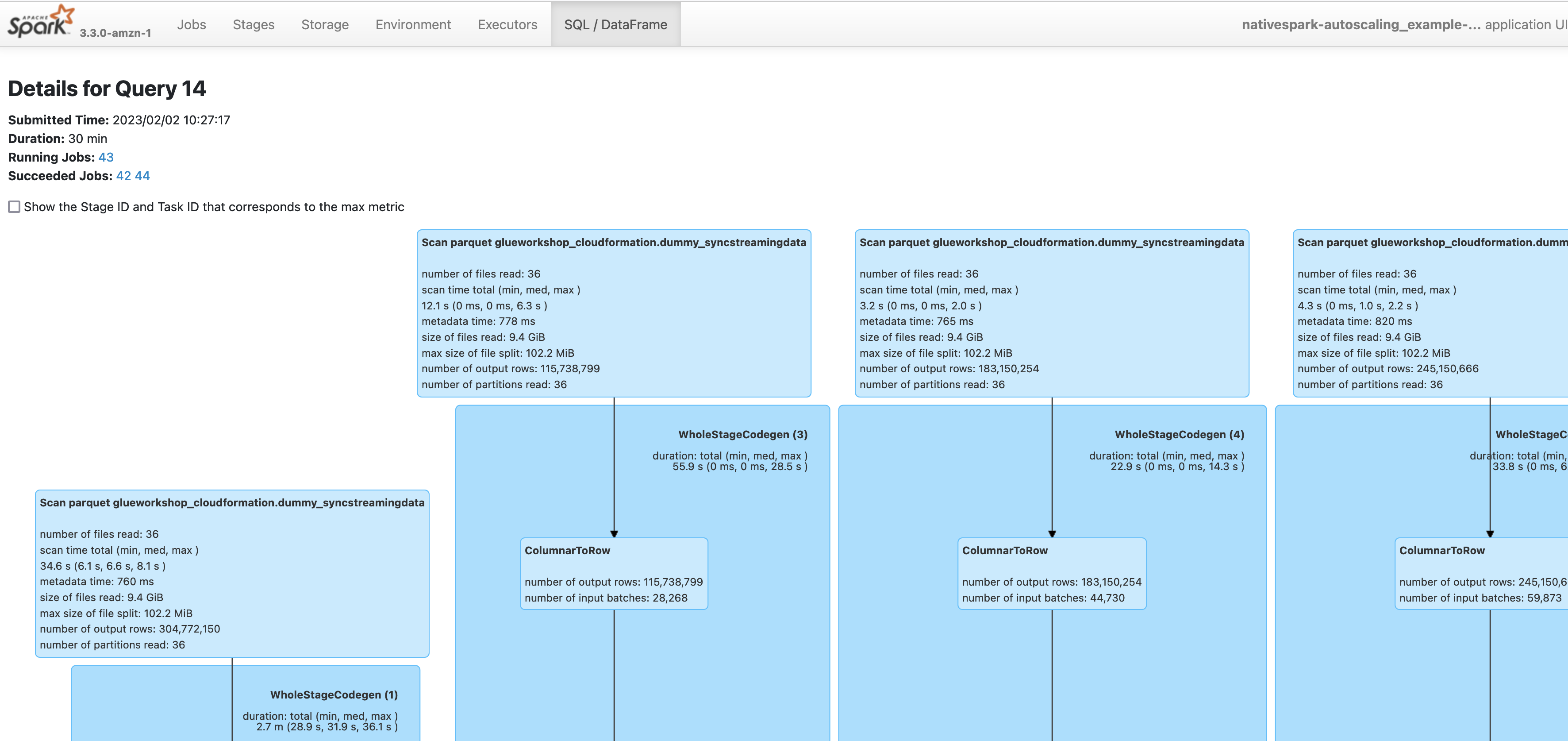
How to use it with AWS Glue
To enable the Spark UI feature using the AWS console, please set Spark UI parameters of your AWS Glue job;

To enable the Spark UI feature using the AWS CLI, pass in the following job parameters to AWS Glue jobs.
'--enable-spark-ui': 'true' and
'--spark-event-logs-path': 's3://s3-event-log-path'
More AWS Glue configuration guidance, tips and alternative ways of deploying Spark History UI can be found at AWS Glue documentation